It would be great if the export remembered the last time an export was run and gave the option to export all or export just content from > the last export date. I have around 2200 posts, and it takes quite a bit of time to export. I think the Day One import is not going to be a thing I want to repeat (Day One is not doing well with 2200 posts suddenly added), but would want to be able to do on some kind of regular basis to keep a copy.
Thanks, I think we’ll want to continue to improve this. With Day One in particular, more of an incremental update makes more sense.
This feature has become more complicated than I expected, so I think for 2.1 we’ll keep it as a basic export and not incremental, although we could revisit this later. A work-around in the meantime is to always export into a separate Day One journal, then batch select only the new journal entries and drag them into your real journal.
Fair enough! I did want to note that even with that many posts, though I did have to quit Day One after the import to get it working, the import did work well. The only oddity, which I don’t think is fixable or in scope, was that my use of shortcodes around images resulted in code blocks in Day One and not with the images in the post. My guess is it’s pushing markdown unprocessed and not HTML, which is going to be correct for 99% of people.
Yeah, that’s true, the export runs with the original Markdown, before it has been processed by Hugo. I wonder if we should start storing the post-processed text too so that we have more control over things like this.
Interested in DayOne integration since Patrick Rhone talk. Looks like on free plan it would properly import though cos limited to 1 photo per post, right?
of the other 3 options, which would people say is the most ‘standard’ likely interoperable in future? Guessing either Blog Archive or Markdown
this is what Markdown export folder looks like:
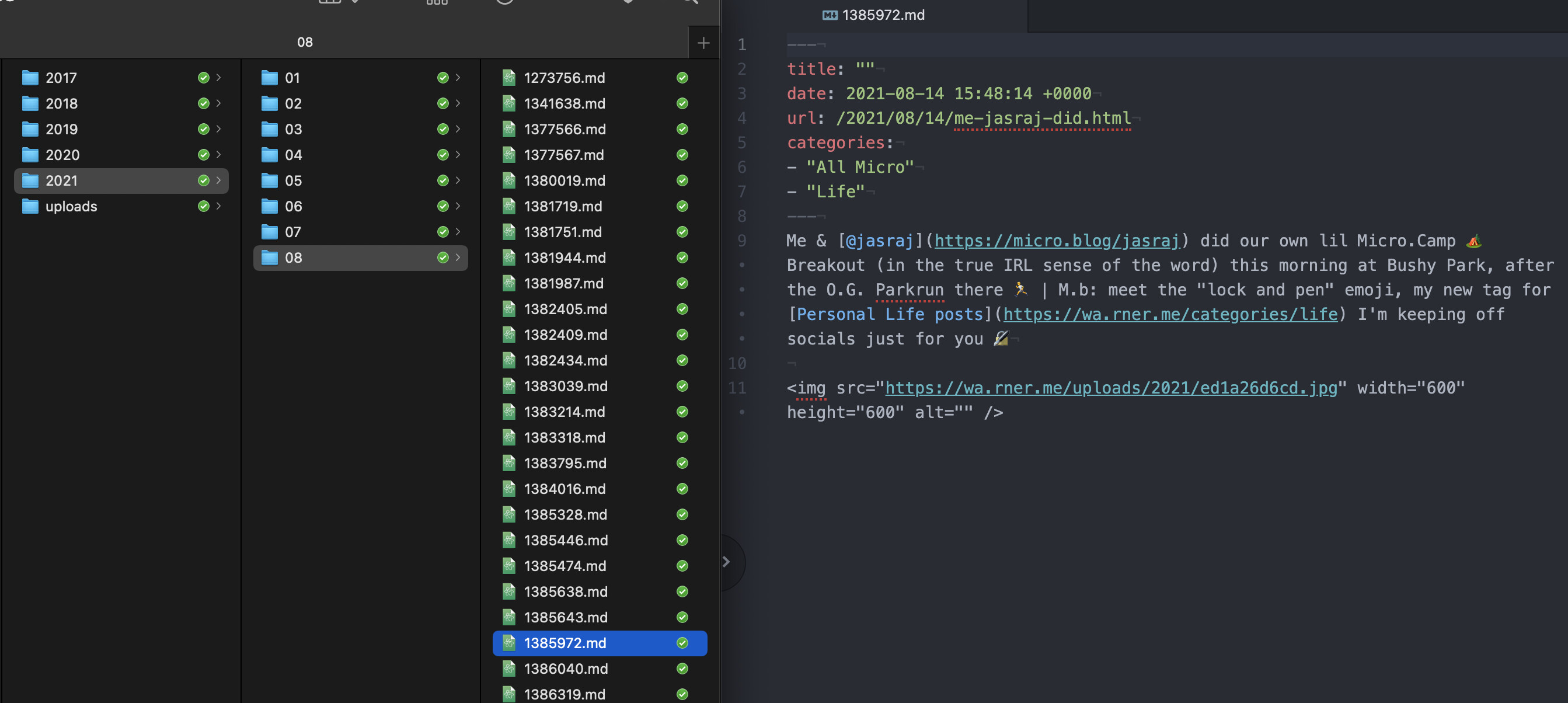
I’m pleasantly surprised at how well structured it is by day & month.
In terms of propensity for import, it’s pretty cool it has the structured tags at the top.
One slight potential weakness is that the uploads referenced are hard-coded including original.domain/date before the filename code, which is simply what the uploads are saved as.
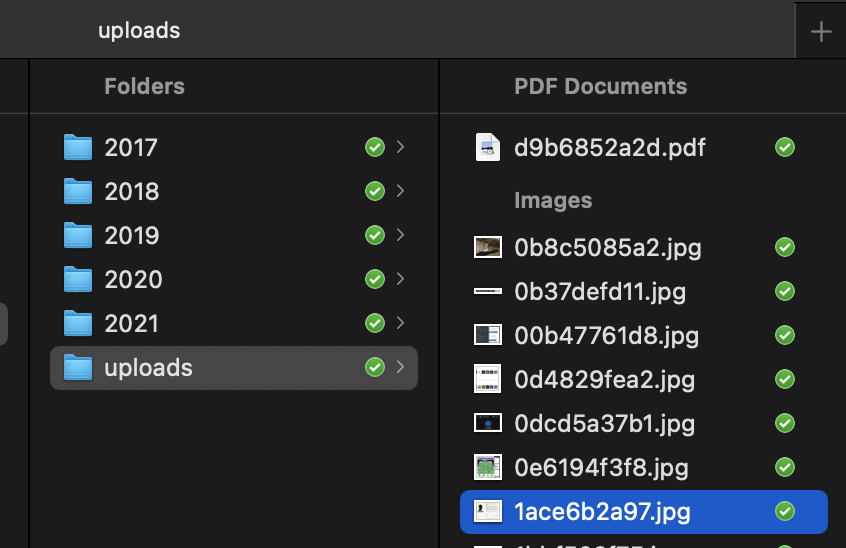
The filename code could be pulled out and added to the list at the top perhaps @manton to make it easier to reference the correct upload.
I’m also impressed that it’s successfully downloaded the richer-media:
especially as I only uploaded them on a trial of $10 premium plan (though I plan to upgrade on next yearly renewal to podcast more)
I’m guessing Blog Archive is probably less nice for a human to look at, but probably more easily imports into more places?
I think you’re probably right on that.
I think we should improve this in the future so that the image references are relative. Glad it’s working, though!
has anyone tried importing to Day One to use their Book printing Book Printing
Patrick Rhone recommended in Micro.Camp?
I noticed you can only process order from iOS now, wondering if you could still import on Mac.
I just discovered the Day One export, yep I’m that fast  and I have two comments:
and I have two comments:
-
As mentioned above, incremental export would make sense.
-
I note that images that have been uploaded using Mimi behaves different that those who have been uploaded using a “micro blog app”. To me it looks like the markdown code for an image is what gets added to Day One, which then displays the image as an external image. Images uploaded by a “micro blog app” seem to be inserted as an image in Day One. In other words, it looks like images uploaded using Mimi isn’t included in the export to Day One. Am I correct in how it works?
That’s interesting. Seems like a bug, we should convert the Markdown to HTML temporarily while processing the export so that it works consistently.
1 Like
Finally decided to restart using Day One, so I could have a unified journal of private and public notes. But faced the same problem, Markdown images aren’t imported properly, even though I prefer this format for longevity purposes.
@manton it’d be great to have it converted, the way full-HTML entries look in Day One is great.
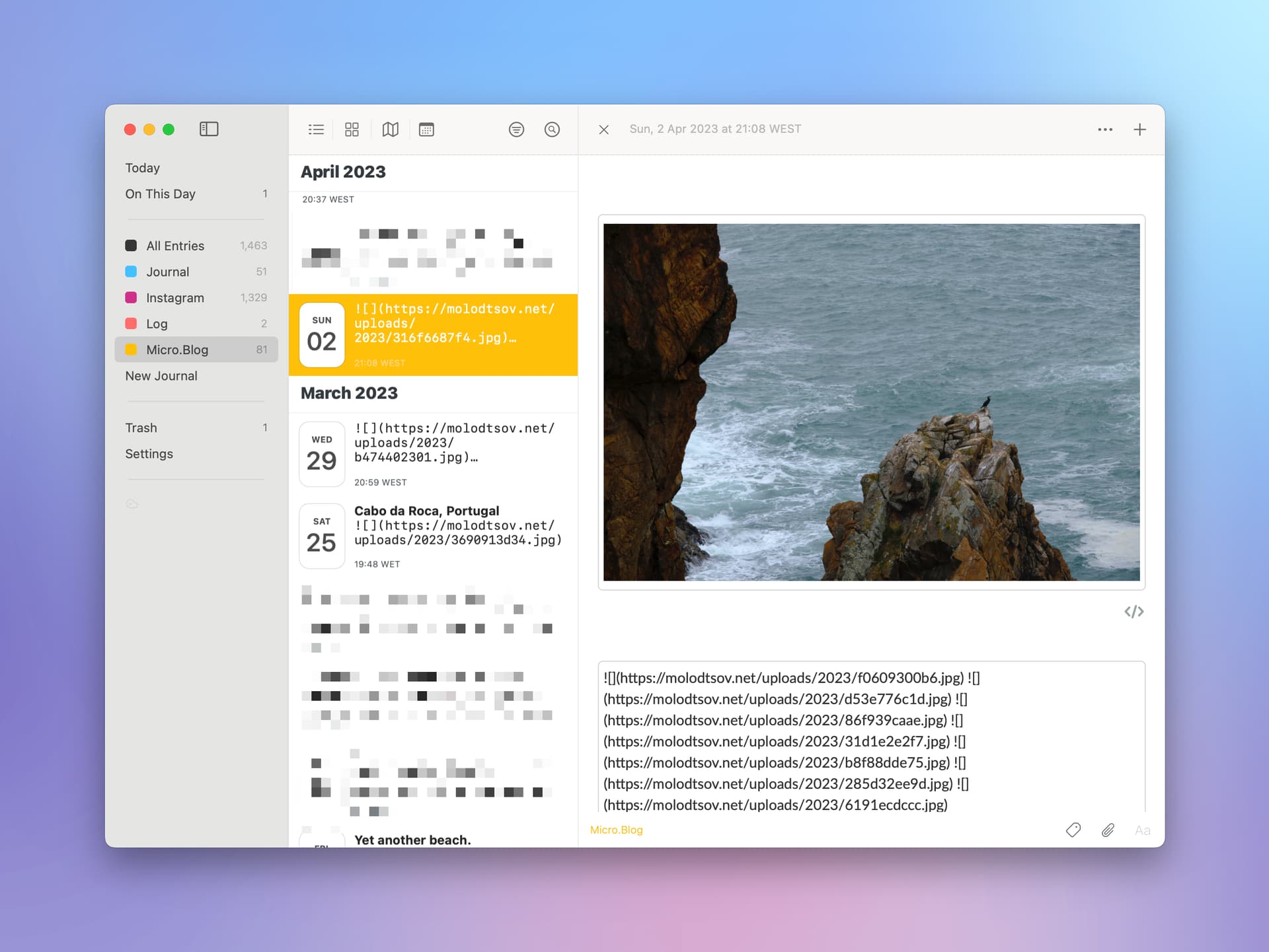
Even with HTML, I don’t think I have been able to auto-import multiple images in one entry.
@pratik works for me, but only if the images are embedded with HTML.
Perhaps coz I’m using IFTTT. Maybe I misunderstood. So in DayOne, you are hotlinking to images on Micro.blog using Markdown and not directly uploading to DayOne?
@pratik continuing the topic, I used the Export option in the Micro.Blog macOS app.
Sorry I dropped the ball on this. I actually have a comment in the Mac source code to fix this… Micro.blog for Mac needs to recognize the Markdown and extract the photo URLs so they can be sent to Day One, like they do for HTML tags. Should be straightforward so I’ll make sure it’s in the next release.
Apologies for waking up an old thread, but I just exported from micro.blog to DayOne expecting that it wouldn’t duplicate the entries. Would be nice if the date range was an option to prevent this as I do think I’d occasionally want to back it up.
I agree about a setting to specify a date range. Another option if you haven’t tried it yet is the cross-posting on the web (under Sources) for Day One. That can copy each post to Day One as it’s posted, so might work for you to supplement the initial export. It does require Day One Premium, though.